2015.12.17 理工学図書館TA 情報科学研究科 M2 加藤
スクレイピングとは普段使っているブラウザ(Internet Explorer, Google Chrome, Safariなど)ではなくプログラムからインターネットにアクセスする技術です。注意事項
として人間が操作するのとは異なりプログラムからは高速アクセスが可能です。使い方を誤ると事件になる場合(Librahack事件)もありますのでウェブサイトの利用規約を先に確認するなど十分注意してください。プログラムからアクセスしていいかを確認するためにRubyではRobotexというライブラリを併用することをおすすめします。
また、電子ジャーナル・電子ブックのウェブサイトに対してスクレイピングを行うと、機械的なダウンロードと判断されて大阪大学全体の利用が停止される恐れがありますので絶対に行わないでください。
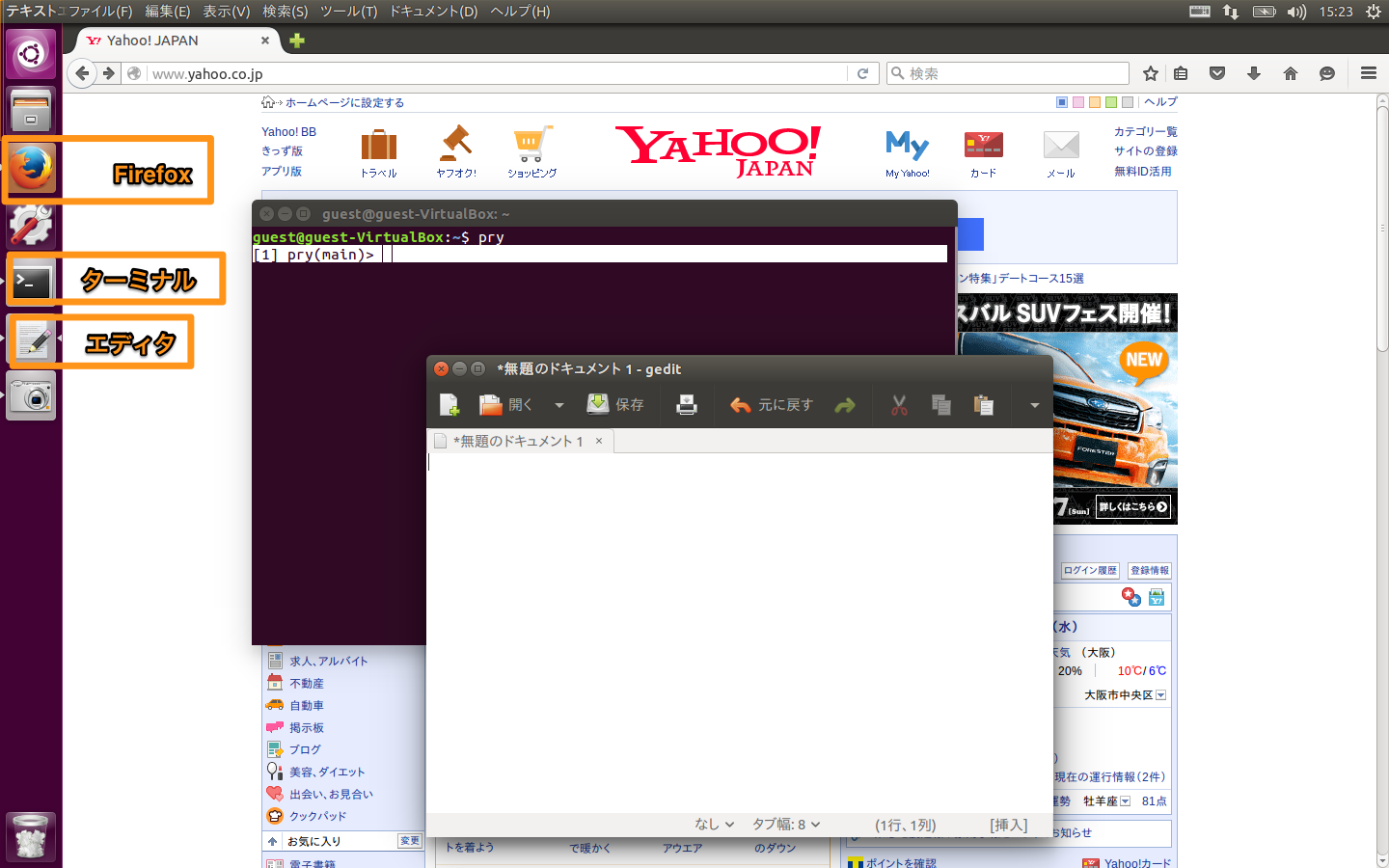
こちらで用意した環境を使用するか、自前でライブラリのインストールを行って下さい。以下はUbuntu(Linux)とFirefoxを用いて説明をしますので,自分で環境を用意する方は適宜読み替えて下さい.
Virtualbox(https://www.virtualbox.org)をインストールしたあと, Ubuntu.ovaをダウンロードし起動。
*「Ubuntu.ova」のリンクをクリックすればダウンロードできます。ファイルサイズが2.2GBと大きいのでインターネット接続環境の良いところでダウンロードしてください。
*「Ubuntu.ova」をダウンロードした際に、別の拡張子(.tar)に変わってしまった場合は、ファイルの名前の変更で、拡張子部分を「.ova」に修正してください。
cd Desktopでデスクトップに移動lsでファイル一覧を出すをputs "hello, world"puts 2**10
test.rbという名前でデスクトップに保存ruby test.rbで実行Rubyにてpry,robotex,nokogiriをインストールしてあればOKです。
pryと打ってみる[1] pry(main)>が出てきたらputs "hello, world"と打ってみるexitでターミナルに戻る注) PryはRubyを1行ずつ動かすための環境
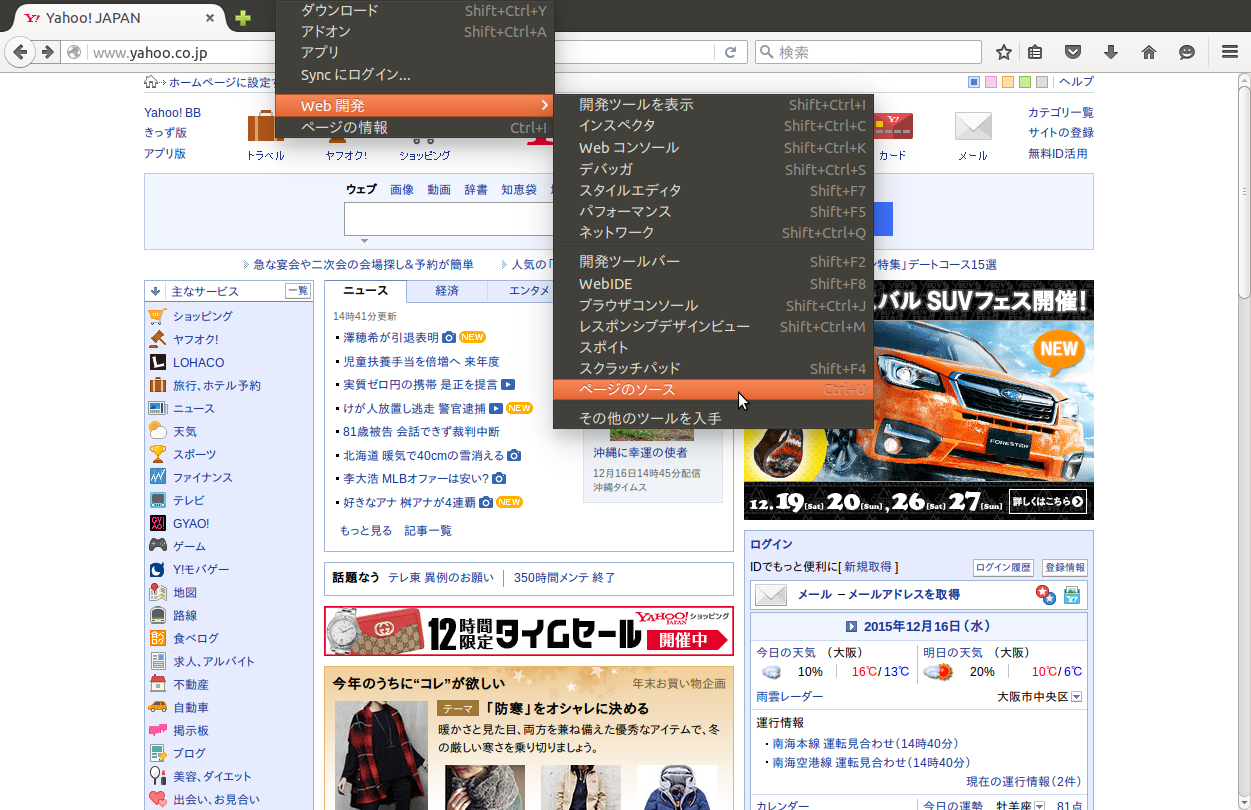
普段目にするウェブページはhtmlで表現されている。そのhtmlの中身がどうなっているかをsample.htmlを使って簡単に紹介する。
HTMLのサンプルHello, everyone!What I like is ...applebaseballcello
htmlの中身は<tag> ? </tag>の入れ子(繰り返し)構造で表現されているtagはタグと呼び、特定のタグを用いると表示をウェブページの表示を制御できる。<title>を使うとウェブページのタイトルを決定できる。<ul>, <li>では箇条書きを表現できる。<div>で囲まれた部分は「あるひとかたまり」としての意味を持つが、ウェブページの見た目には影響しない。class, idを付けることができるが、これはhtml作成者が分かりやすくするためでありdivと同様見た目には影響しない。XMLに準拠した文書(=HTML)の特定の部分を指定する言語(Wikipedia)
/html/head/titleとなる。<li>のように同じタグが並んでいる場合はどうすればよいだろうか。<li>(apple)はli[1]と表現できる。puts "This is a pen." => "This is a pen."というメッセージを出す。array = ["oolong tea", "cola", "beer"]のとき、puts array[0] => "oolong tea"。候補が複数ある時htmlと違って"0"スタート。配列の追加はarray << "water"というふうに行う。candidatesが複数のものの候補(もちろん配列を含む)であるとき、その全てについて処理を行いたい場合は次のように記述する。candidates.each do |candidate|# 何か処理# 例えばputs candidateとすればcandidatesそれぞれの要素を出力するend
pryに入り# nokogiriという便利なライブラリを使う
sample.htmlの読み込み# practice.rbと同じディレクトリにあるsample.htmlを開くfile = File.open('sample.html')# それをdocという名前のnokogiri形式に変換doc = Nokogiri::HTML(file)
# xpathでtitleを探してtitleという名前をつけるtitle = doc.xpath('/html/head/title')# putsは画面に出力する関数。titleとtitle.textの違いは?puts titleputs title.text
<li>のように複数ある場合はどうなるかfavorites = doc.xpath('??????')puts favoritesputs favorites.text
favorites = doc.xpath('?????')puts favoritesputs favorites.text
favorites = doc.xpath('')puts ??????puts ??????
pryでexitと打ちターミナルに戻り、ruby practice.rbで同じ結果が出ることを確認
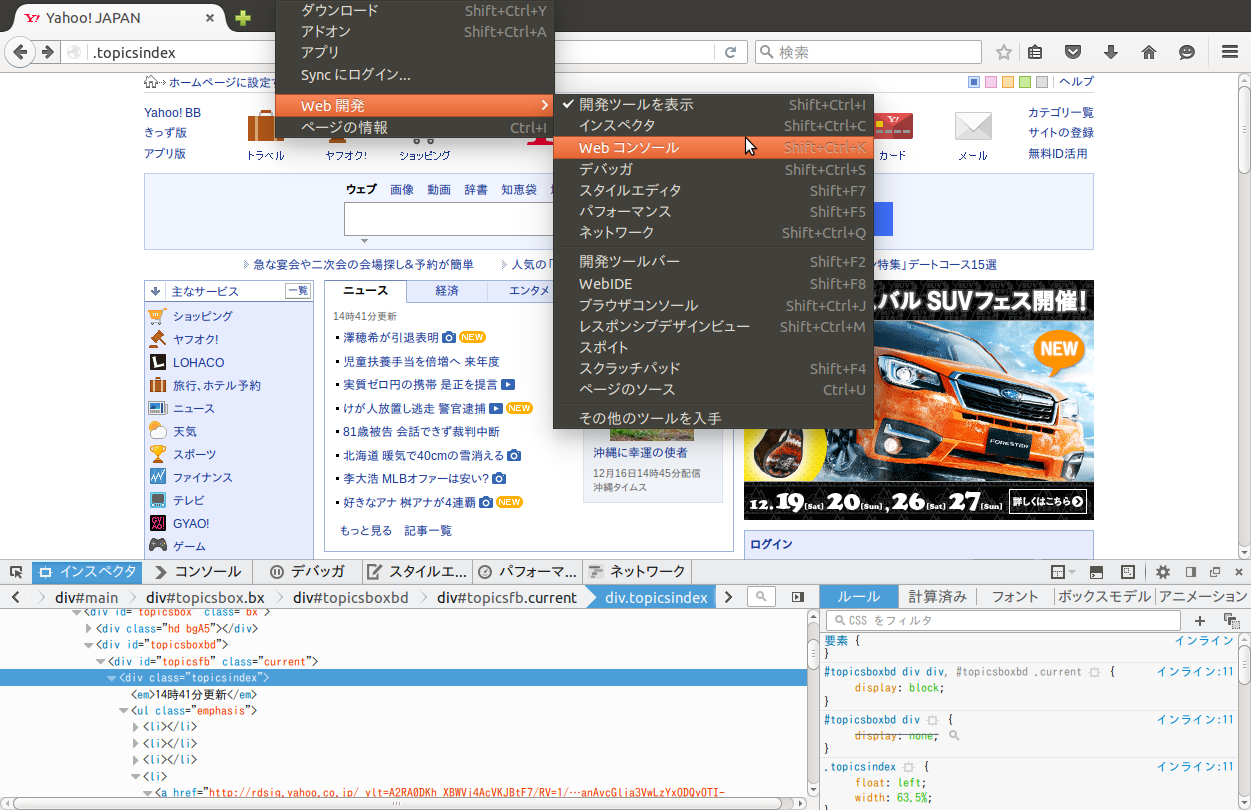
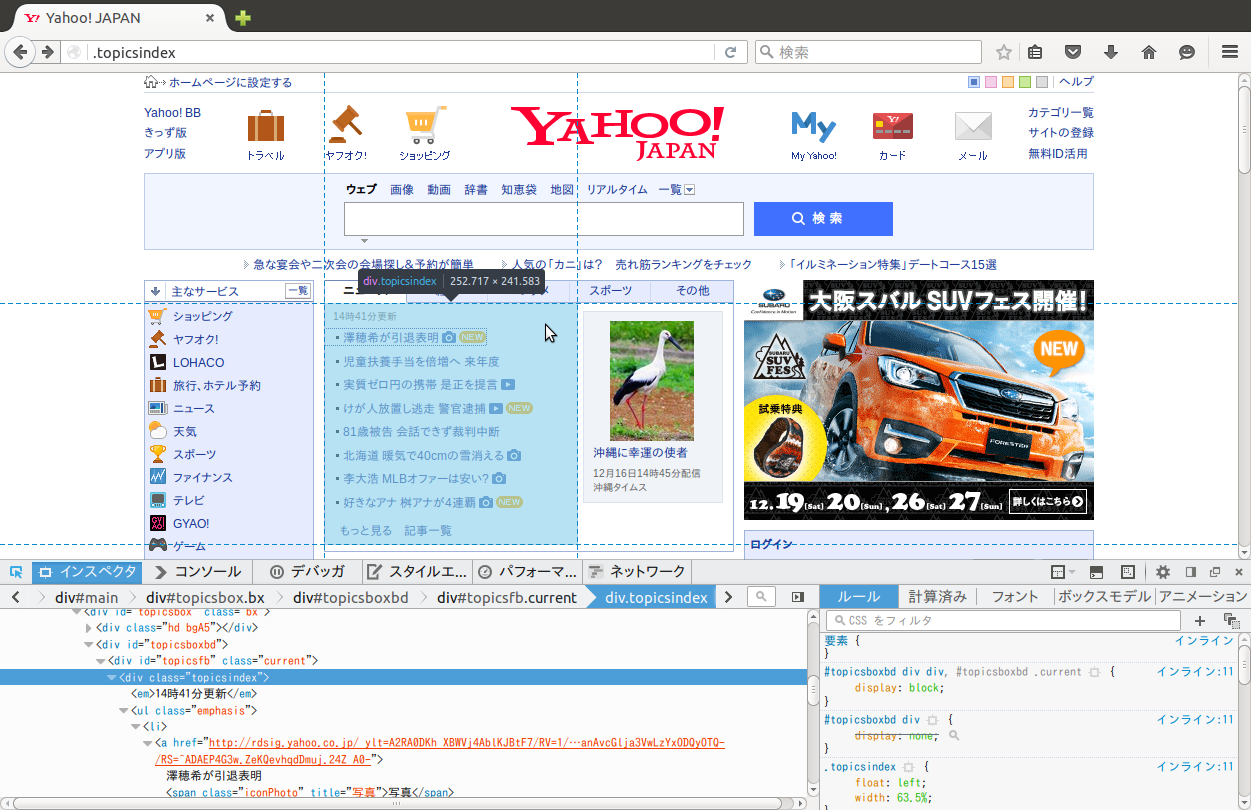
class="favorite"である<li>はxpathでli[@class="favorite"]となるdiv」を表したい場合は//divと書く。//div[@class="favorite"]# ローカルではなくウェブページを開くのに必要# 実際のウェブページをスクレイピングしていいか確認できるライブラリ
robotex = Robotex.newurl = 'http://www.yahoo.co.jp/'
if robotex.allowed?(url)=beginスクレイピングしていい場合はここが実行elseだめならここが実行end=end
UserAgent = 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)'html = open(url, 'User-Agent' => UserAgent).read
doc = Nokogiri::HTML(html)doc.xpath('?????').each do |node|
./A/B/Cnode.xpath('.??????').each do |a|puts a.text
endendelseputs 'Now allowed :-('end
pryでexitと打ちターミナルに戻り、ruby yahoo.rbで同じ結果が出ることを確認ruby title.rb# ローカルではなくウェブページを開くのに必要# 実際のウェブページをスクレイピングしていいか確認できるライブラリrobotex = Robotex.newurl = '?????'if robotex.allowed?(url)# おまじないUserAgent = 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)'html = open(url, 'User-Agent' => UserAgent).readdoc = Nokogiri::HTML(html)doc.xpath('?????').each do |node|node.xpath('.?????').each do |a|puts a.textendendelseputs 'Now allowed :-('end
catで検索して出てきた画像を取得することを考えるpryへ入りまずはライブラリを使うsave_image(画像のurl)filename = File.basename(url)open(filename.to_s, 'wb') do |file|open(url) do |data|file.write(data.read)endendend
url = "?????"# picsは画像のurlを入れるための配列(最初は空)pics = []robotex = Robotex.new
docとして使用if robotex.allowed?("https://www.flickr.com") thendoc = Nokogiri::HTML(open(url))
doc.xpath("?????").each do |link|
puts linkendend
.attr("属性名")を使う。if robotex.allowed?("https://www.flickr.com") thendoc = Nokogiri::HTML(open(url))doc.xpath("?????").each do |link|puts ?????endend
↓transform: translate(758px, 1015px); -webkit-transform: translate(758px, 1015px); -ms-transform: translate(758px, 1015px); width: 302px; height: 187px; background-image: url(//c4.staticflickr.com/8/7012/6672150457_420d61007d_n.jpg)
/私は.です/のとき私は◯ですを取り出すことができる。a = "あろうことか私は熊ですと答えてしまった。"puts a.match(/私は.です/).to_s #=> 私は熊です
//とおしりのjpgに着目して、その正規表現は/????/と考えられるのでif robotex.allowed?("https://www.flickr.com") thendoc = Nokogiri::HTML(open(url))doc.xpath("?????").each do |link|puts link.attr('style').match(//).to_sendend
"abc" + "def" #=> "abcdef"とすればよいのでif robotex.allowed?("https://www.flickr.com") thendoc = Nokogiri::HTML(open(url))doc.xpath("?????").each do |link|puts "" + link.attr('style').match(//).to_sendend
picsに保存しておくif robotex.allowed?("https://www.flickr.com") thendoc = Nokogiri::HTML(open(url))doc.xpath("?????").each do |link|pics << "" + link.attr('style').match(//).to_sendend
pics[0, 5].each do |pic_url|save_image(pic_url)end
ruby flickr.rbを実行。